Introduction
This post provides a comprehensive walkthrough of designing a distributed job scheduler system, a common interview question at fintech companies. We’ll design a system that can handle millions of jobs, ensure reliable execution, and scale horizontally to meet requirements for financial operations.
Table of Contents
- Problem Statement
- Requirements
- Capacity Estimation
- Core Entities
- API
- Data Flow
- Database Design
- High-Level Design
- Deep Dive
- Conclusion
Problem Statement
Build a service/system that can support defining and running jobs on a schedule. Requirements:
-
Should be able to create jobs: Users can create/define jobs via an API with execution commands, required resources, priority, schedule, and other configuration.
-
Should be able to schedule and run jobs: The system must efficiently schedule jobs and execute them according to their schedule, priority, and resource availability.
-
Should be able to report failures and successes: The system must track and report job execution outcomes (success/failure), with detailed failure reasons and success metrics.
- Should be reliable and have strong guarantees about its job runs: The system must provide strong guarantees:
- At-least-once execution: Jobs will execute at least once (may execute multiple times for retries)
- Exactly-once semantics where possible: For idempotent jobs
- No job loss: Jobs are never lost, even during system failures
- Guaranteed execution: Scheduled jobs will execute if resources are available
- Atomic operations: Job state transitions are atomic
- Should be able to view logs and status of running jobs, as well as previously finished jobs: Provide comprehensive interfaces to:
- View real-time status of running jobs
- Access execution logs (stdout, stderr)
- View historical job executions
- Query job status and history
- Should be able to handle when a job takes longer to run than expected (SLA): The system must handle SLA violations:
- Detect when jobs exceed their expected execution time
- Take appropriate actions (timeout, kill, alert, extend)
- Track SLA compliance metrics
- Support configurable SLA policies
Describe the system architecture, including components and technology choices, considering system scalability and reliability.
Requirements
Functional Requirements
Core Features:
- Create Jobs (Job Definition)
- Create jobs via REST API with complete job definition
- Job metadata: command, resources (CPU, memory), priority, schedule, timeout, retry policy
- Support different job types: one-time, recurring, scheduled, cron-based
- Job dependencies (Job B runs after Job A completes)
- Job configuration and environment variables
- Validation of job definitions before creation
- Schedule and Run Jobs
- Schedule jobs based on time (cron, interval, specific time)
- Priority-based scheduling (higher priority jobs run first)
- Resource-aware scheduling (match jobs to available resources)
- Fair scheduling (prevent starvation, ensure fairness)
- Support different scheduling algorithms (FIFO, priority queue, fair share)
- Handle job dependencies before execution
- Report Failures and Successes
- Track job execution outcomes (success/failure)
- Detailed failure reporting: error codes, error messages, stack traces
- Success metrics: execution time, resource usage, output size
- Failure classification: transient vs. permanent errors
- Failure aggregation and reporting
- Success/failure rate tracking per job, user, team
- Reliability and Strong Guarantees
- At-least-once execution: Jobs execute at least once (may retry)
- Exactly-once semantics: For idempotent jobs with idempotency keys
- No job loss guarantee: Jobs persisted to database, never lost
- Guaranteed execution: Scheduled jobs will execute if resources available
- Atomic state transitions: Job status changes are atomic
- Durability: All job definitions and executions persisted
- Consistency: Strong consistency for job metadata
- Transaction support: Critical operations use transactions
- View Logs and Status
- Real-time status of running jobs (queued, scheduled, running, completed, failed)
- Execution logs: stdout, stderr with real-time streaming
- Job history: all previous executions with status
- Execution details: start time, end time, duration, resource usage
- Log search and filtering capabilities
- Log retention and archival policies
- Handle SLA Violations (Long-Running Jobs)
- SLA definition: expected execution time per job
- SLA monitoring: track execution time vs. expected time
- SLA violation detection: alert when job exceeds SLA
- SLA violation handling:
- Timeout and kill jobs that exceed max execution time
- Alert on SLA violations
- Extend SLA for long-running jobs (with approval)
- Track SLA compliance metrics
- Support for configurable SLA policies (strict, flexible, warning-only)
- Additional Features
- Job cancellation and pause/resume
- Resource quota management
- Worker node failure handling
- Horizontal scaling of all components
Non-Functional Requirements
Scale:
- 10+ million jobs per day
- 100,000+ concurrent jobs
- Thousands of worker nodes
- Millions of users
Performance:
- Job submission latency: < 100ms
- Job scheduling latency: < 50ms
- Job status query latency: < 50ms
- 99.9% jobs scheduled within 1 second
Reliability:
- 99.99% uptime
- No job loss guarantee
- At-least-once execution guarantee (exactly-once for idempotent jobs)
- Strong consistency for job metadata
- Atomic state transitions
- Automatic failover
- Data durability (all writes persisted)
Availability:
- Multi-region deployment
- No single point of failure
- Graceful degradation
Financial Compliance:
- Complete audit trail
- Job execution logs retention
- Security and access control
Clarifying Questions
Scale:
- Q: What’s the expected number of jobs per day?
- A: 10+ million jobs per day, with peaks up to 100,000 jobs per minute
Resources:
- Q: What types of resources need to be managed?
- A: CPU cores, memory (GB), disk space, GPU (optional), network bandwidth
Job Types:
- Q: What types of jobs need to be supported?
- A: Batch jobs, real-time jobs, scheduled jobs, recurring jobs
Priority:
- Q: How many priority levels?
- A: 0-1000, with 1000 being highest priority
Execution Environment:
- Q: What execution environments?
- A: Docker containers, Kubernetes pods, VMs
Retry Policy:
- Q: What retry strategies?
- A: Exponential backoff, max retries, retry on specific error types
Dependencies:
- Q: Do jobs have dependencies?
- A: Yes, support job dependencies (Job B depends on Job A)
Capacity Estimation
Storage Estimates
Job Metadata:
- Each job: ~2KB metadata
- 10M jobs/day × 2KB = 20GB/day
- With 30-day retention: ~600GB
- With 1-year retention: ~7.3TB
Job Execution Logs:
- Each execution: ~10KB logs
- 10M jobs/day × 10KB = 100GB/day
- With 30-day retention: ~3TB
- With 1-year retention: ~36.5TB
Job Status Updates:
- Each status update: ~500 bytes
- 10M jobs × 5 status updates = 50M updates/day
- 50M × 500 bytes = 25GB/day
Throughput Estimates
Write QPS:
- Job submissions: 100,000 jobs/minute = ~1,667 QPS
- Status updates: 50M updates/day = ~580 QPS
- Total writes: ~2,250 QPS
Read QPS:
- Job status queries: 500,000 QPS (users checking status)
- Job history queries: 100,000 QPS
- Total reads: ~600,000 QPS
Execution QPS:
- Job executions: 100,000 jobs/minute = ~1,667 QPS
Network Bandwidth
- Job submissions: 1,667 QPS × 2KB = 3.3MB/s
- Status updates: 580 QPS × 500 bytes = 290KB/s
- Job queries: 600,000 QPS × 1KB = 600MB/s
- Total: ~600MB/s
Resource Capacity
Worker Nodes:
- 1,000 worker nodes
- Each node: 32 CPU cores, 128GB RAM
- Total: 32,000 CPU cores, 128TB RAM
Database:
- Need to handle 2,250 write QPS and 600,000 read QPS
- Requires sharding and read replicas
Core Entities
Job
- Attributes: job_id, job_name, job_type, command, resources, priority, schedule, status, created_at, updated_at
- Relationships: Has executions, has dependencies, belongs to user/team
Job Execution
- Attributes: execution_id, job_id, worker_node_id, status, started_at, completed_at, exit_code, logs_url
- Relationships: Belongs to job, runs on worker node
Worker Node
- Attributes: worker_id, hostname, ip_address, available_resources, status, last_heartbeat
- Relationships: Executes jobs, reports status
Schedule
- Attributes: schedule_id, job_id, cron_expression, timezone, next_run_time, enabled
- Relationships: Belongs to job
API
Job Submission
POST /api/v1/jobs
Authorization: Bearer {token}
Request:
{
"job_name": "portfolio_rebalancing",
"job_type": "batch",
"command": "python /app/scripts/rebalance.py",
"execution_env": "docker",
"resources": {
"cpu_cores": 4,
"memory_gb": 8,
"disk_gb": 10
},
"scheduling": {
"priority": 750,
"max_execution_time": 3600
},
"retry": {
"max_retries": 3,
"retry_policy": "exponential_backoff"
}
}
Response: 201 Created
{
"job_id": "550e8400-e29b-41d4-a716-446655440000",
"status": "queued",
"created_at": "2025-11-03T10:00:00Z",
"estimated_start_time": "2025-11-03T10:00:05Z"
}
Get Job Status
GET /api/v1/jobs/{job_id}
Response: 200 OK
{
"job_id": "550e8400-e29b-41d4-a716-446655440000",
"status": "running",
"created_at": "2025-11-03T10:00:00Z",
"started_at": "2025-11-03T10:00:05Z",
"current_execution": {
"execution_id": "exec-uuid",
"worker_node_id": "worker-123",
"status": "running",
"started_at": "2025-11-03T10:00:05Z"
},
"retry_count": 0
}
Cancel Job
DELETE /api/v1/jobs/{job_id}
Response: 200 OK
{
"job_id": "550e8400-e29b-41d4-a716-446655440000",
"status": "cancelled",
"cancelled_at": "2025-11-03T10:05:00Z"
}
List Jobs
GET /api/v1/jobs?status=running&limit=100&offset=0
Response: 200 OK
{
"jobs": [
{
"job_id": "uuid-1",
"job_name": "job-1",
"status": "running",
"created_at": "2025-11-03T10:00:00Z"
}
],
"total": 1500,
"limit": 100,
"offset": 0
}
Data Flow
Job Submission Flow
- Client submits job → API Gateway
- API Gateway → Job Submission Service
- Job Submission Service validates job definition
- Job Submission Service → Database (store job)
- Job Submission Service → Message Queue (job created event)
- Message Queue → Scheduler Service (trigger scheduling)
- Response returned to client
Job Scheduling Flow
- Scheduler Service polls for jobs to schedule
- Scheduler Service checks job dependencies
- Scheduler Service matches job to available worker
- Scheduler Service → Database (update job status to “scheduled”)
- Scheduler Service → Message Queue (job scheduled event)
- Message Queue → Executor Service (execute job)
Job Execution Flow
- Executor Service receives job execution request
- Executor Service → Worker Node (dispatch job)
- Worker Node executes job
- Worker Node → Log Storage (stream logs)
- Worker Node → Executor Service (status updates)
- Executor Service → Database (update execution status)
- Executor Service → Message Queue (execution completed event)
Database Design
Schema Design
Jobs Table:
CREATE TABLE jobs (
job_id VARCHAR(36) PRIMARY KEY,
job_name VARCHAR(255) NOT NULL,
job_type ENUM('batch', 'streaming', 'scheduled') NOT NULL,
command TEXT NOT NULL,
execution_env VARCHAR(50),
resources JSON,
priority INT DEFAULT 500,
status ENUM('queued', 'scheduled', 'running', 'completed', 'failed', 'cancelled') DEFAULT 'queued',
user_id VARCHAR(36),
team_id VARCHAR(36),
created_at TIMESTAMP,
updated_at TIMESTAMP,
INDEX idx_status_priority (status, priority DESC),
INDEX idx_user_id (user_id),
INDEX idx_created_at (created_at)
);
Job Executions Table:
CREATE TABLE job_executions (
execution_id VARCHAR(36) PRIMARY KEY,
job_id VARCHAR(36) NOT NULL,
worker_node_id VARCHAR(36),
status ENUM('running', 'completed', 'failed', 'cancelled') NOT NULL,
started_at TIMESTAMP,
completed_at TIMESTAMP,
exit_code INT,
logs_url VARCHAR(512),
resource_usage JSON,
FOREIGN KEY (job_id) REFERENCES jobs(job_id),
INDEX idx_job_id (job_id),
INDEX idx_status (status),
INDEX idx_started_at (started_at)
);
Worker Nodes Table:
CREATE TABLE worker_nodes (
worker_id VARCHAR(36) PRIMARY KEY,
hostname VARCHAR(255) NOT NULL,
ip_address VARCHAR(45),
available_resources JSON,
status ENUM('active', 'inactive', 'draining') DEFAULT 'active',
last_heartbeat TIMESTAMP,
INDEX idx_status (status),
INDEX idx_last_heartbeat (last_heartbeat)
);
Job Schedules Table:
CREATE TABLE job_schedules (
schedule_id VARCHAR(36) PRIMARY KEY,
job_id VARCHAR(36) NOT NULL,
cron_expression VARCHAR(255),
timezone VARCHAR(50),
next_run_time TIMESTAMP,
enabled BOOLEAN DEFAULT TRUE,
FOREIGN KEY (job_id) REFERENCES jobs(job_id),
INDEX idx_next_run_time (next_run_time),
INDEX idx_enabled (enabled)
);
Database Sharding Strategy
Shard by Job ID:
- Use consistent hashing to distribute jobs across shards
- Job data and executions on same shard for locality
- Enables efficient job queries
High-Level Design
System Components
┌─────────────────────────────────────────────────────────────┐
│ Client Applications │
│ (Trading System, Portfolio Service, Analytics Service) │
└──────────────────────┬──────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ API Gateway │
│ (Authentication, Rate Limiting, Load Balance) │
└──────────────────────┬──────────────────────────────────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Job │ │ Scheduler │ │ Executor │
│ Submission │ │ Service │ │ Service │
│ Service │ │ │ │ │
└──────────────┘ └──────────────┘ └──────────────┘
│ │ │
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────────────────────────┐
│ Data Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Database │ │ Message │ │ Cache │ │
│ │ (PostgreSQL) │ │ Queue │ │ (Redis) │ │
│ │ │ │ (Kafka) │ │ │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└──────────────────────┬──────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Worker Cluster │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Worker │ │ Worker │ │ Worker │ │
│ │ Node 1 │ │ Node 2 │ │ Node N │ │
│ │ │ │ │ │ │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
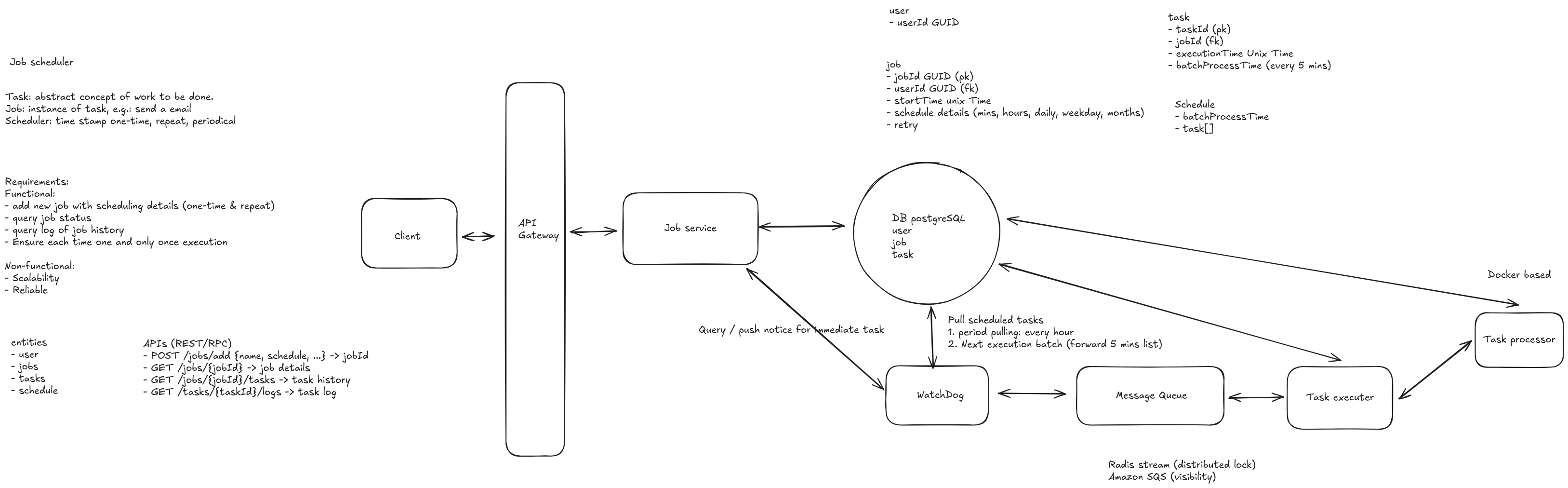
Core Services
- API Gateway: Handles client requests, authentication, rate limiting
- Job Submission Service: Accepts job submissions, validates, stores metadata
- Scheduler Service: Determines when and where to execute jobs
- Executor Service: Manages job execution on worker nodes
- Monitoring Service: Tracks job status, metrics, and alerts
- Resource Manager: Manages worker node resources and allocation
Data Stores
- Database (PostgreSQL): Job metadata, execution history, resource allocation
- Message Queue (Kafka): Async job processing, event streaming
- Cache (Redis): Job status, recent executions, worker node metadata
- Object Storage (S3): Job logs, large outputs
Deep Dive
Component Design
Detailed Design
Database Schema
Jobs Table:
CREATE TABLE jobs (
job_id UUID PRIMARY KEY,
user_id UUID NOT NULL,
job_name VARCHAR(255),
job_type VARCHAR(50) NOT NULL, -- 'batch', 'realtime', 'scheduled', 'recurring'
command TEXT NOT NULL,
execution_env VARCHAR(50), -- 'docker', 'kubernetes', 'vm'
-- Resources
cpu_cores INTEGER NOT NULL,
memory_gb INTEGER NOT NULL,
disk_gb INTEGER,
gpu_count INTEGER DEFAULT 0,
-- Scheduling
priority INTEGER DEFAULT 500, -- 0-1000
max_execution_time INTEGER, -- seconds (hard limit)
expected_execution_time INTEGER, -- seconds (warning threshold)
timeout_seconds INTEGER,
sla_policy VARCHAR(20) DEFAULT 'flexible', -- 'strict', 'flexible', 'warning_only'
-- Retry
max_retries INTEGER DEFAULT 3,
retry_policy VARCHAR(50), -- 'exponential_backoff', 'fixed', 'immediate'
retry_delay_seconds INTEGER DEFAULT 60,
-- Status
status VARCHAR(20) DEFAULT 'queued', -- 'queued', 'scheduled', 'running', 'completed', 'failed', 'cancelled'
-- Timing
created_at TIMESTAMP NOT NULL,
scheduled_at TIMESTAMP,
started_at TIMESTAMP,
completed_at TIMESTAMP,
next_retry_at TIMESTAMP,
-- Metadata
job_config JSONB,
tags JSONB,
-- Indexes
INDEX idx_status_priority (status, priority DESC, created_at),
INDEX idx_user_id (user_id),
INDEX idx_scheduled_at (scheduled_at),
INDEX idx_next_retry_at (next_retry_at)
);
Job Executions Table:
CREATE TABLE job_executions (
execution_id UUID PRIMARY KEY,
job_id UUID REFERENCES jobs(job_id),
worker_node_id VARCHAR(255),
-- Execution details
status VARCHAR(20) NOT NULL, -- 'running', 'completed', 'failed', 'cancelled', 'timeout'
exit_code INTEGER,
error_message TEXT,
error_type VARCHAR(50), -- 'timeout', 'out_of_memory', 'network_error', etc.
stack_trace TEXT,
-- Timing
started_at TIMESTAMP NOT NULL,
completed_at TIMESTAMP,
duration_ms INTEGER,
-- SLA
expected_execution_time_ms INTEGER,
max_execution_time_ms INTEGER,
sla_met BOOLEAN,
sla_violation_percentage DECIMAL(5,2),
-- Resources
cpu_cores_used INTEGER,
memory_gb_used INTEGER,
disk_gb_used INTEGER,
-- Output
output_size_bytes BIGINT,
-- Logs
stdout_log_url TEXT,
stderr_log_url TEXT,
log_stream_url TEXT,
-- Retry info
retry_count INTEGER DEFAULT 0,
INDEX idx_job_id (job_id),
INDEX idx_worker_node_id (worker_node_id),
INDEX idx_started_at (started_at),
INDEX idx_status (status),
INDEX idx_sla_met (sla_met)
);
SLA Events Table:
CREATE TABLE sla_events (
event_id UUID PRIMARY KEY,
job_id UUID REFERENCES jobs(job_id),
execution_id UUID REFERENCES job_executions(execution_id),
event_type VARCHAR(20) NOT NULL, -- 'sla_warning', 'sla_violation'
expected_time_ms INTEGER NOT NULL,
actual_time_ms INTEGER NOT NULL,
overrun_ms INTEGER,
action_taken VARCHAR(50), -- 'alert', 'kill', 'extend', 'none'
timestamp TIMESTAMP NOT NULL,
INDEX idx_job_id (job_id),
INDEX idx_execution_id (execution_id),
INDEX idx_timestamp (timestamp)
);
Job Dependencies Table:
CREATE TABLE job_dependencies (
job_id UUID REFERENCES jobs(job_id),
depends_on_job_id UUID REFERENCES jobs(job_id),
dependency_type VARCHAR(20), -- 'completion', 'success', 'failure'
PRIMARY KEY (job_id, depends_on_job_id)
);
Worker Nodes Table:
CREATE TABLE worker_nodes (
node_id VARCHAR(255) PRIMARY KEY,
node_type VARCHAR(50), -- 'docker', 'kubernetes', 'vm'
-- Resources
total_cpu_cores INTEGER NOT NULL,
total_memory_gb INTEGER NOT NULL,
total_disk_gb INTEGER,
total_gpu_count INTEGER DEFAULT 0,
-- Available resources
available_cpu_cores INTEGER NOT NULL,
available_memory_gb INTEGER NOT NULL,
available_disk_gb INTEGER,
available_gpu_count INTEGER DEFAULT 0,
-- Status
status VARCHAR(20) DEFAULT 'active', -- 'active', 'draining', 'inactive'
health_status VARCHAR(20) DEFAULT 'healthy', -- 'healthy', 'unhealthy', 'degraded'
-- Location
region VARCHAR(50),
zone VARCHAR(50),
-- Metadata
last_heartbeat TIMESTAMP NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
INDEX idx_status_health (status, health_status),
INDEX idx_available_resources (available_cpu_cores, available_memory_gb)
);
Resource Allocations Table:
CREATE TABLE resource_allocations (
allocation_id UUID PRIMARY KEY,
job_id UUID REFERENCES jobs(job_id),
execution_id UUID REFERENCES job_executions(execution_id),
worker_node_id VARCHAR(255) REFERENCES worker_nodes(node_id),
cpu_cores INTEGER NOT NULL,
memory_gb INTEGER NOT NULL,
disk_gb INTEGER,
gpu_count INTEGER DEFAULT 0,
allocated_at TIMESTAMP NOT NULL,
released_at TIMESTAMP,
INDEX idx_job_id (job_id),
INDEX idx_worker_node_id (worker_node_id),
INDEX idx_allocated_at (allocated_at)
);
Job Submission Service
Responsibilities:
- Accept job submission requests
- Validate job parameters
- Store job metadata in database
- Publish job to scheduling queue
API Design:
POST /api/v1/jobs
Content-Type: application/json
{
"job_name": "portfolio_rebalancing",
"job_type": "batch",
"command": "python /app/scripts/rebalance.py --portfolio-id=123",
"execution_env": "docker",
"resources": {
"cpu_cores": 4,
"memory_gb": 8,
"disk_gb": 10,
"gpu_count": 0
},
"scheduling": {
"priority": 750,
"max_execution_time": 3600, // seconds (hard limit)
"expected_execution_time": 1800, // seconds (warning threshold)
"timeout_seconds": 7200,
"sla_policy": "flexible" // 'strict', 'flexible', 'warning_only'
},
"retry": {
"max_retries": 3,
"retry_policy": "exponential_backoff",
"retry_delay_seconds": 60
},
"dependencies": [
{
"job_id": "uuid-of-dependent-job",
"dependency_type": "completion"
}
],
"tags": {
"team": "portfolio",
"environment": "production"
}
}
Response:
{
"job_id": "uuid-here",
"status": "queued",
"created_at": "2025-11-03T10:00:00Z",
"estimated_start_time": "2025-11-03T10:00:05Z"
}
Implementation:
class JobSubmissionService:
def submit_job(self, job_request):
# Validate job request
self.validate_job_request(job_request)
# Create job record
job = self.create_job_record(job_request)
# Check dependencies
if job_request.dependencies:
self.validate_dependencies(job_request.dependencies)
# Store in database
job_id = self.db.create_job(job)
# Publish to scheduling queue
self.kafka.produce('job-submissions', {
'job_id': job_id,
'priority': job.priority,
'resources': job.resources
})
# Cache job status
self.redis.set(f"job:{job_id}:status", "queued", ex=3600)
return job_id
Scheduler Service
Responsibilities:
- Pull jobs from queue
- Find available worker nodes
- Match jobs to workers based on resources and priority
- Allocate resources
- Trigger job execution
Scheduling Algorithm:
class SchedulerService:
def schedule_jobs(self):
while True:
# Get queued jobs ordered by priority
queued_jobs = self.db.get_queued_jobs(
limit=1000,
order_by=['priority DESC', 'created_at ASC']
)
# Get available worker nodes
available_workers = self.get_available_workers()
# Match jobs to workers
assignments = self.match_jobs_to_workers(
queued_jobs,
available_workers
)
# Allocate resources and trigger execution
for job, worker in assignments:
self.allocate_resources(job, worker)
self.trigger_execution(job, worker)
def match_jobs_to_workers(self, jobs, workers):
assignments = []
# Sort jobs by priority (highest first)
sorted_jobs = sorted(jobs, key=lambda j: j.priority, reverse=True)
# Sort workers by available resources
sorted_workers = sorted(
workers,
key=lambda w: (w.available_cpu_cores, w.available_memory_gb),
reverse=True
)
for job in sorted_jobs:
for worker in sorted_workers:
if self.can_allocate(job, worker):
assignments.append((job, worker))
# Update worker available resources
worker.available_cpu_cores -= job.cpu_cores
worker.available_memory_gb -= job.memory_gb
break
return assignments
def can_allocate(self, job, worker):
return (
worker.status == 'active' and
worker.health_status == 'healthy' and
worker.available_cpu_cores >= job.cpu_cores and
worker.available_memory_gb >= job.memory_gb and
worker.available_disk_gb >= job.disk_gb and
worker.available_gpu_count >= job.gpu_count
)
Scheduling Strategies:
- Priority-Based Scheduling
- Jobs with higher priority execute first
- Prevents starvation with aging
- Fair Share Scheduling
- Allocate resources fairly across users/teams
- Prevents one user from monopolizing resources
- Resource-Aware Scheduling
- Match job requirements to available resources
- Optimize resource utilization
- Location-Aware Scheduling
- Schedule jobs on worker nodes in same region
- Reduce latency and data transfer costs
Executor Service
Responsibilities:
- Execute jobs on worker nodes
- Monitor job execution
- Handle job failures and retries
- Collect execution logs
- Update job status
Implementation:
class ExecutorService:
def execute_job(self, job, worker_node):
# Create execution record
execution = self.db.create_execution(job.job_id, worker_node.node_id)
# Allocate resources
allocation = self.resource_manager.allocate(
job, worker_node
)
try:
# Update job status
self.update_job_status(job.job_id, 'running', execution.execution_id)
# Execute based on environment
if job.execution_env == 'docker':
result = self.execute_docker(job, worker_node)
elif job.execution_env == 'kubernetes':
result = self.execute_kubernetes(job, worker_node)
else:
result = self.execute_vm(job, worker_node)
# Monitor SLA during execution
self.sla_monitor.start_monitoring(job, execution)
# Handle result
if result.exit_code == 0:
self.handle_success(job, execution, result)
else:
self.handle_failure(job, execution, result)
except TimeoutError as e:
self.handle_timeout(job, execution, e)
except Exception as e:
self.handle_exception(job, execution, e)
finally:
# Stop SLA monitoring
self.sla_monitor.stop_monitoring(execution.execution_id)
# Release resources
self.resource_manager.release(allocation)
def handle_success(self, job, execution, result):
# Calculate execution time
duration_ms = (datetime.now() - execution.started_at).total_seconds() * 1000
# Check SLA compliance
sla_met = duration_ms <= job.max_execution_time * 1000 if job.max_execution_time else True
sla_violation_pct = 0
if job.expected_execution_time and duration_ms > job.expected_execution_time * 1000:
sla_violation_pct = ((duration_ms - job.expected_execution_time * 1000) / (job.expected_execution_time * 1000)) * 100
# Update execution
self.db.update_execution(
execution.execution_id,
status='completed',
exit_code=0,
completed_at=datetime.now(),
duration_ms=int(duration_ms),
sla_met=sla_met,
sla_violation_percentage=sla_violation_pct,
cpu_cores_used=result.cpu_usage,
memory_gb_used=result.memory_usage,
output_size_bytes=result.output_size
)
# Report success
self.reporting_service.report_execution_outcome(
execution,
{
'status': 'success',
'exit_code': 0,
'duration_ms': duration_ms,
'cpu_usage': result.cpu_usage,
'memory_usage': result.memory_usage,
'output_size': result.output_size
}
)
# Update job status
self.update_job_status(job.job_id, 'completed', execution.execution_id)
# Track SLA compliance
if job.expected_execution_time:
self.sla_tracker.track_sla_compliance(
job.job_id,
duration_ms,
job.expected_execution_time * 1000
)
# Trigger dependent jobs
self.trigger_dependent_jobs(job.job_id, 'success')
def handle_failure(self, job, execution, result):
# Calculate execution time
duration_ms = (datetime.now() - execution.started_at).total_seconds() * 1000 if execution.started_at else 0
# Classify error
error_type = self.classify_error(result.error_message)
# Log failure with detailed information
self.db.update_execution(
execution.execution_id,
status='failed',
exit_code=result.exit_code,
error_message=result.error_message,
error_type=error_type,
stack_trace=result.stack_trace,
completed_at=datetime.now(),
duration_ms=int(duration_ms),
cpu_cores_used=result.cpu_usage if hasattr(result, 'cpu_usage') else None,
memory_gb_used=result.memory_usage if hasattr(result, 'memory_usage') else None
)
# Report failure
self.reporting_service.report_execution_outcome(
execution,
{
'status': 'failed',
'exit_code': result.exit_code,
'error_message': result.error_message,
'error_type': error_type,
'stack_trace': result.stack_trace,
'duration_ms': duration_ms
}
)
# Check if should retry
if execution.retry_count < job.max_retries:
self.schedule_retry(job, execution)
else:
# Mark job as failed
self.update_job_status(job.job_id, 'failed', execution.execution_id)
self.trigger_dependent_jobs(job.job_id, 'failure')
def handle_timeout(self, job, execution, error):
# Handle timeout (SLA violation)
duration_ms = (datetime.now() - execution.started_at).total_seconds() * 1000
# Kill the job process
self.kill_execution(execution.execution_id)
# Update execution
self.db.update_execution(
execution.execution_id,
status='timeout',
exit_code=-1,
error_message='Job exceeded maximum execution time',
error_type='timeout',
completed_at=datetime.now(),
duration_ms=int(duration_ms)
)
# Report timeout
self.reporting_service.report_execution_outcome(
execution,
{
'status': 'failed',
'exit_code': -1,
'error_message': 'Job exceeded maximum execution time',
'error_type': 'timeout',
'duration_ms': duration_ms
}
)
# Check if should retry
if execution.retry_count < job.max_retries:
self.schedule_retry(job, execution)
else:
self.update_job_status(job.job_id, 'failed', execution.execution_id)
def classify_error(self, error_message):
# Classify error type for better reporting
error_lower = error_message.lower() if error_message else ''
if 'timeout' in error_lower:
return 'timeout'
elif 'memory' in error_lower or 'oom' in error_lower:
return 'out_of_memory'
elif 'permission' in error_lower or 'access denied' in error_lower:
return 'permission_error'
elif 'network' in error_lower or 'connection' in error_lower:
return 'network_error'
elif 'not found' in error_lower:
return 'not_found'
elif 'disk' in error_lower or 'space' in error_lower:
return 'disk_error'
else:
return 'unknown'
def schedule_retry(self, job, execution):
# Calculate retry delay
if job.retry_policy == 'exponential_backoff':
delay = job.retry_delay_seconds * (2 ** execution.retry_count)
else:
delay = job.retry_delay_seconds
# Schedule retry
retry_time = datetime.now() + timedelta(seconds=delay)
self.db.update_job(
job.job_id,
status='queued',
next_retry_at=retry_time,
retry_count=execution.retry_count + 1
)
# Publish to scheduling queue
self.kafka.produce('job-submissions', {
'job_id': job.job_id,
'priority': job.priority,
'is_retry': True
})
Resource Manager
Responsibilities:
- Track worker node resources
- Allocate resources to jobs
- Release resources when jobs complete
- Monitor resource utilization
- Handle worker node failures
Implementation:
class ResourceManager:
def allocate(self, job, worker_node):
# Create allocation record
allocation = self.db.create_allocation(
job.job_id,
worker_node.node_id,
job.cpu_cores,
job.memory_gb,
job.disk_gb,
job.gpu_count
)
# Update worker node available resources
self.db.update_worker_node(
worker_node.node_id,
available_cpu_cores=worker_node.available_cpu_cores - job.cpu_cores,
available_memory_gb=worker_node.available_memory_gb - job.memory_gb,
available_disk_gb=worker_node.available_disk_gb - job.disk_gb,
available_gpu_count=worker_node.available_gpu_count - job.gpu_count
)
# Cache allocation
self.redis.set(
f"allocation:{allocation.allocation_id}",
json.dumps(allocation.to_dict()),
ex=3600
)
return allocation
def release(self, allocation):
# Update worker node available resources
worker = self.db.get_worker_node(allocation.worker_node_id)
self.db.update_worker_node(
allocation.worker_node_id,
available_cpu_cores=worker.available_cpu_cores + allocation.cpu_cores,
available_memory_gb=worker.available_memory_gb + allocation.memory_gb,
available_disk_gb=worker.available_disk_gb + allocation.disk_gb,
available_gpu_count=worker.available_gpu_count + allocation.gpu_count
)
# Mark allocation as released
self.db.update_allocation(
allocation.allocation_id,
released_at=datetime.now()
)
# Remove from cache
self.redis.delete(f"allocation:{allocation.allocation_id}")
Failure and Success Reporting Service
Responsibilities:
- Track job execution outcomes (success/failure)
- Report detailed failure information
- Collect success metrics
- Aggregate failure/success statistics
- Generate failure reports
Implementation:
class FailureSuccessReportingService:
def report_execution_outcome(self, execution, result):
# Store execution outcome
outcome = {
'execution_id': execution.execution_id,
'job_id': execution.job_id,
'status': result.status, # 'success' or 'failed'
'exit_code': result.exit_code,
'error_message': result.error_message if result.status == 'failed' else None,
'error_type': self.classify_error(result.error_message) if result.status == 'failed' else None,
'stack_trace': result.stack_trace if result.status == 'failed' else None,
'execution_time_ms': result.duration_ms,
'resource_usage': {
'cpu_cores_used': result.cpu_usage,
'memory_gb_used': result.memory_usage,
'disk_gb_used': result.disk_usage
},
'output_size_bytes': result.output_size if result.status == 'success' else None,
'timestamp': datetime.now()
}
# Store in database
self.db.create_execution_outcome(outcome)
# Update job statistics
self.update_job_statistics(execution.job_id, outcome)
# Publish event for real-time updates
self.kafka.produce('job-outcomes', outcome)
# Generate alerts if needed
if outcome['status'] == 'failed':
self.generate_failure_alert(outcome)
def classify_error(self, error_message):
# Classify error type
if 'timeout' in error_message.lower():
return 'timeout'
elif 'memory' in error_message.lower() or 'oom' in error_message.lower():
return 'out_of_memory'
elif 'permission' in error_message.lower() or 'access denied' in error_message.lower():
return 'permission_error'
elif 'network' in error_message.lower() or 'connection' in error_message.lower():
return 'network_error'
elif 'not found' in error_message.lower():
return 'not_found'
else:
return 'unknown'
def update_job_statistics(self, job_id, outcome):
# Update job-level statistics
stats = self.db.get_job_statistics(job_id)
if outcome['status'] == 'success':
stats['success_count'] += 1
stats['total_execution_time_ms'] += outcome['execution_time_ms']
stats['avg_execution_time_ms'] = stats['total_execution_time_ms'] / stats['success_count']
else:
stats['failure_count'] += 1
stats['failure_types'][outcome['error_type']] = stats['failure_types'].get(outcome['error_type'], 0) + 1
stats['total_executions'] += 1
stats['success_rate'] = stats['success_count'] / stats['total_executions']
self.db.update_job_statistics(job_id, stats)
Failure Reporting API:
GET /api/v1/jobs/{job_id}/failures
Response:
{
"job_id": "uuid-here",
"total_failures": 5,
"failure_rate": 0.05,
"failure_breakdown": {
"timeout": 2,
"out_of_memory": 1,
"network_error": 1,
"unknown": 1
},
"recent_failures": [
{
"execution_id": "exec-uuid-1",
"failed_at": "2025-11-03T10:05:00Z",
"error_type": "timeout",
"error_message": "Job exceeded maximum execution time",
"duration_ms": 7200000
}
]
}
GET /api/v1/jobs/{job_id}/successes
Response:
{
"job_id": "uuid-here",
"total_successes": 95,
"success_rate": 0.95,
"avg_execution_time_ms": 325000,
"p50_execution_time_ms": 300000,
"p95_execution_time_ms": 450000,
"p99_execution_time_ms": 600000
}
Strong Guarantees Implementation
Reliability Guarantees:
- At-Least-Once Execution
- Jobs stored in database before scheduling
- Jobs queued in Kafka (durable, replicated)
- Retry mechanism ensures execution
- Idempotency keys for deduplication
- Exactly-Once Semantics (for Idempotent Jobs)
- Idempotency key per job
- Checkpoint mechanism
- Deduplication at execution level
- Transactional state updates
- No Job Loss Guarantee
- All job definitions persisted to database (ACID)
- Jobs queued in Kafka (durable, replicated)
- Database replication (primary + replicas)
- Backup and recovery mechanisms
- Guaranteed Execution
- Jobs remain in queue until executed
- Automatic retry on failures
- Worker node failover and job rescheduling
- No job dropped from queue
- Atomic State Transitions
- Database transactions for state changes
- Optimistic locking to prevent race conditions
- Distributed locks for critical sections
- Event sourcing for audit trail
Implementation:
class JobStateManager:
def transition_job_state(self, job_id, from_state, to_state):
# Use database transaction for atomic state transition
with self.db.transaction():
# Check current state
job = self.db.get_job(job_id)
if job.status != from_state:
raise StateTransitionError(f"Job {job_id} is in {job.status}, not {from_state}")
# Update state atomically
self.db.update_job(
job_id,
status=to_state,
updated_at=datetime.now()
)
# Log state transition for audit
self.db.create_state_transition_log(
job_id=job_id,
from_state=from_state,
to_state=to_state,
timestamp=datetime.now()
)
# Publish state change event
self.kafka.produce('job-state-changes', {
'job_id': job_id,
'from_state': from_state,
'to_state': to_state,
'timestamp': datetime.now().isoformat()
})
Monitoring Service
Responsibilities:
- Track job status in real-time
- Collect metrics and analytics
- Generate alerts
- Provide job history and logs
- Real-time log streaming
- Historical log access
Real-Time Status Tracking:
class MonitoringService:
def get_job_status(self, job_id):
# Check cache first
cached_status = self.redis.get(f"job:{job_id}:status")
if cached_status:
return json.loads(cached_status)
# Query database
job = self.db.get_job(job_id)
execution = self.db.get_current_execution(job_id)
status = {
'job_id': job_id,
'status': job.status,
'created_at': job.created_at.isoformat(),
'scheduled_at': job.scheduled_at.isoformat() if job.scheduled_at else None,
'started_at': job.started_at.isoformat() if job.started_at else None,
'completed_at': job.completed_at.isoformat() if job.completed_at else None,
'current_execution': {
'execution_id': execution.execution_id if execution else None,
'worker_node_id': execution.worker_node_id if execution else None,
'status': execution.status if execution else None,
'started_at': execution.started_at.isoformat() if execution and execution.started_at else None,
'duration_ms': self.calculate_duration(execution) if execution else None
} if execution else None,
'retry_count': job.retry_count,
'max_retries': job.max_retries
}
# Cache for 1 minute
self.redis.setex(
f"job:{job_id}:status",
60,
json.dumps(status)
)
return status
Log Viewing Service:
class LogViewingService:
def get_job_logs(self, job_id, execution_id=None):
# Get execution logs
if execution_id:
execution = self.db.get_execution(execution_id)
else:
execution = self.db.get_current_execution(job_id)
if not execution:
return None
logs = {
'execution_id': execution.execution_id,
'stdout_log_url': execution.stdout_log_url,
'stderr_log_url': execution.stderr_log_url,
'log_stream_url': self.get_log_stream_url(execution.execution_id)
}
return logs
def stream_logs(self, execution_id, log_type='stdout'):
# Stream logs in real-time
log_url = self.get_log_url(execution_id, log_type)
# For real-time streaming, use WebSocket or Server-Sent Events
# For large logs, stream from S3
return self.s3_client.get_object_stream(log_url)
def search_logs(self, job_id, query, limit=100):
# Search logs using Elasticsearch or similar
# Index logs for searchability
results = self.elasticsearch.search(
index='job-logs',
body={
'query': {
'bool': {
'must': [
{'match': {'job_id': job_id}},
{'match': {'content': query}}
]
}
}
},
size=limit
)
return results
API Design:
GET /api/v1/jobs/{job_id}
Response:
{
"job_id": "uuid-here",
"status": "running",
"created_at": "2025-11-03T10:00:00Z",
"scheduled_at": "2025-11-03T10:00:05Z",
"started_at": "2025-11-03T10:00:05Z",
"completed_at": null,
"current_execution": {
"execution_id": "exec-uuid",
"worker_node_id": "worker-123",
"status": "running",
"started_at": "2025-11-03T10:00:05Z",
"duration_ms": 15000
},
"retry_count": 0,
"max_retries": 3
}
GET /api/v1/jobs/{job_id}/executions
Response:
{
"executions": [
{
"execution_id": "exec-uuid-1",
"status": "completed",
"started_at": "2025-11-03T10:00:05Z",
"completed_at": "2025-11-03T10:05:30Z",
"duration_ms": 325000,
"exit_code": 0,
"worker_node_id": "worker-123"
}
],
"total": 1
}
GET /api/v1/jobs/{job_id}/logs?execution_id={execution_id}
Response:
{
"execution_id": "exec-uuid",
"stdout_log_url": "https://s3.amazonaws.com/logs/job-uuid/stdout.log",
"stderr_log_url": "https://s3.amazonaws.com/logs/job-uuid/stderr.log",
"log_stream_url": "wss://api.example.com/logs/exec-uuid/stream"
}
GET /api/v1/jobs/{job_id}/executions?limit=10&offset=0
Response:
{
"executions": [
{
"execution_id": "exec-uuid-1",
"status": "completed",
"started_at": "2025-11-03T10:00:05Z",
"completed_at": "2025-11-03T10:05:30Z",
"duration_ms": 325000,
"exit_code": 0,
"worker_node_id": "worker-123",
"logs": {
"stdout_log_url": "...",
"stderr_log_url": "..."
}
}
],
"total": 100
}
SLA Monitoring and Violation Handling Service
Responsibilities:
- Monitor job execution time against SLA
- Detect SLA violations
- Handle jobs that exceed expected execution time
- Track SLA compliance metrics
- Support configurable SLA policies
SLA Definition:
class SLADefinition:
def __init__(self, job_id, expected_execution_time_ms, max_execution_time_ms, sla_policy):
self.job_id = job_id
self.expected_execution_time_ms = expected_execution_time_ms # Warning threshold
self.max_execution_time_ms = max_execution_time_ms # Hard limit
self.sla_policy = sla_policy # 'strict', 'flexible', 'warning_only'
SLA Monitoring:
class SLAMonitoringService:
def monitor_running_jobs(self):
# Poll running jobs and check SLA
running_jobs = self.db.get_running_jobs()
for job in running_jobs:
execution = self.db.get_current_execution(job.job_id)
if not execution:
continue
# Calculate execution duration
duration_ms = (datetime.now() - execution.started_at).total_seconds() * 1000
# Get SLA definition
sla = self.get_sla_definition(job.job_id)
# Check SLA violations
if duration_ms > sla.expected_execution_time_ms:
self.handle_sla_warning(job, execution, duration_ms, sla)
if duration_ms > sla.max_execution_time_ms:
self.handle_sla_violation(job, execution, duration_ms, sla)
def handle_sla_warning(self, job, execution, duration_ms, sla):
# Log warning
self.db.create_sla_event(
job_id=job.job_id,
execution_id=execution.execution_id,
event_type='sla_warning',
expected_time_ms=sla.expected_execution_time_ms,
actual_time_ms=duration_ms,
timestamp=datetime.now()
)
# Send alert if policy requires
if sla.sla_policy in ['strict', 'flexible']:
self.alerting.send_warning(
f"Job {job.job_id} is approaching SLA limit",
{
'job_id': job.job_id,
'expected_time_ms': sla.expected_execution_time_ms,
'actual_time_ms': duration_ms,
'overrun_ms': duration_ms - sla.expected_execution_time_ms
}
)
def handle_sla_violation(self, job, execution, duration_ms, sla):
# Log violation
self.db.create_sla_event(
job_id=job.job_id,
execution_id=execution.execution_id,
event_type='sla_violation',
expected_time_ms=sla.max_execution_time_ms,
actual_time_ms=duration_ms,
timestamp=datetime.now()
)
# Handle based on policy
if sla.sla_policy == 'strict':
# Kill the job
self.kill_job(job, execution, 'SLA violation: exceeded max execution time')
elif sla.sla_policy == 'flexible':
# Send critical alert, allow job to continue
self.alerting.send_critical_alert(
f"Job {job.job_id} has exceeded SLA",
{
'job_id': job.job_id,
'max_time_ms': sla.max_execution_time_ms,
'actual_time_ms': duration_ms
}
)
else: # warning_only
# Just log and alert
self.alerting.send_warning(
f"Job {job.job_id} has exceeded SLA (warning only)",
{'job_id': job.job_id, 'actual_time_ms': duration_ms}
)
def kill_job(self, job, execution, reason):
# Kill the job process
self.executor.kill_execution(execution.execution_id)
# Update execution status
self.db.update_execution(
execution.execution_id,
status='failed',
exit_code=-1,
error_message=reason,
completed_at=datetime.now()
)
# Update job status
self.db.update_job(
job.job_id,
status='failed',
completed_at=datetime.now()
)
# Release resources
allocation = self.db.get_allocation(execution.execution_id)
if allocation:
self.resource_manager.release(allocation)
# Check if should retry
if execution.retry_count < job.max_retries:
self.schedule_retry(job, execution)
SLA Policies:
- Strict Policy
- Kill job when it exceeds max execution time
- Used for time-sensitive jobs
- Prevents resource hogging
- Flexible Policy
- Alert on SLA violation but allow job to continue
- Used for jobs that may legitimately take longer
- Monitor and decide manually
- Warning Only Policy
- Log and alert but take no action
- Used for informational purposes
- Track for capacity planning
SLA Compliance Tracking:
class SLAComplianceTracker:
def track_sla_compliance(self, job_id, execution_time_ms, expected_time_ms):
# Track SLA compliance metrics
compliance = {
'job_id': job_id,
'execution_time_ms': execution_time_ms,
'expected_time_ms': expected_time_ms,
'sla_met': execution_time_ms <= expected_time_ms,
'sla_violation_percentage': ((execution_time_ms - expected_time_ms) / expected_time_ms) * 100 if execution_time_ms > expected_time_ms else 0,
'timestamp': datetime.now()
}
self.db.create_sla_compliance_record(compliance)
# Update aggregated statistics
self.update_sla_statistics(job_id, compliance)
def get_sla_compliance_report(self, job_id, start_date, end_date):
# Generate SLA compliance report
records = self.db.get_sla_compliance_records(job_id, start_date, end_date)
total = len(records)
met = sum(1 for r in records if r['sla_met'])
violated = total - met
return {
'job_id': job_id,
'period': {'start': start_date, 'end': end_date},
'total_executions': total,
'sla_met_count': met,
'sla_violated_count': violated,
'sla_compliance_rate': met / total if total > 0 else 0,
'avg_execution_time_ms': sum(r['execution_time_ms'] for r in records) / total if total > 0 else 0,
'avg_sla_violation_percentage': sum(r['sla_violation_percentage'] for r in records if r['sla_violation_percentage'] > 0) / violated if violated > 0 else 0
}
SLA API Design:
GET /api/v1/jobs/{job_id}/sla-compliance?start_date=2025-11-01&end_date=2025-11-03
Response:
{
"job_id": "uuid-here",
"period": {
"start": "2025-11-01T00:00:00Z",
"end": "2025-11-03T23:59:59Z"
},
"total_executions": 100,
"sla_met_count": 95,
"sla_violated_count": 5,
"sla_compliance_rate": 0.95,
"avg_execution_time_ms": 325000,
"avg_sla_violation_percentage": 15.5
}
POST /api/v1/jobs/{job_id}/extend-sla
Content-Type: application/json
{
"new_max_execution_time_ms": 10800000,
"reason": "Job requires additional processing time",
"approved_by": "user123"
}
Response:
{
"job_id": "uuid-here",
"old_max_execution_time_ms": 7200000,
"new_max_execution_time_ms": 10800000,
"extended_at": "2025-11-03T10:30:00Z"
}
Technology Choices
Database: PostgreSQL
Why PostgreSQL:
- ACID Compliance: Critical for financial systems
- Strong Consistency: Job metadata must be consistent
- Complex Queries: Support for complex scheduling queries
- JSONB Support: Store flexible job configurations
- Mature Ecosystem: Proven reliability
Scaling Strategy:
- Sharding: Shard by user_id or job_id
- Read Replicas: Scale reads with multiple replicas
- Connection Pooling: PgBouncer for connection management
- Partitioning: Partition execution logs by date
Message Queue: Apache Kafka
Why Kafka:
- High Throughput: Handle millions of messages
- Durability: Messages persisted to disk
- Replay Capability: Replay messages for recovery
- Consumer Groups: Multiple consumers process jobs
- Partitioning: Parallel processing
Topic Design:
job-submissions: New job submissionsjob-scheduling: Jobs ready to be scheduledjob-executions: Job execution eventsjob-status-updates: Status change events
Cache: Redis
Why Redis:
- Low Latency: Sub-millisecond access
- Data Structures: Rich data structures (sets, sorted sets, hashes)
- Pub/Sub: Real-time status updates
- Persistence: Optional persistence for reliability
Caching Strategy:
- Job Status: Cache recent job status (TTL: 1 hour)
- Worker Nodes: Cache worker node metadata (TTL: 5 minutes)
- Resource Availability: Cache available resources (TTL: 1 minute)
- Recent Executions: Cache last 100 executions per job
Container Orchestration: Kubernetes
Why Kubernetes:
- Resource Management: Built-in resource allocation
- Auto-scaling: Auto-scale worker nodes
- Health Checks: Automatic health monitoring
- Self-Healing: Restart failed containers
- Namespace Isolation: Multi-tenancy support
Object Storage: Amazon S3
Why S3:
- Durability: 99.999999999% durability
- Scalability: Unlimited storage
- Cost-Effective: Pay for what you use
- Lifecycle Policies: Automatic archival
Storage Structure:
s3://job-logs/
{year}/{month}/{day}/{job_id}/
stdout.log
stderr.log
execution_metadata.json
Scalability Design
Horizontal Scaling
API Gateway:
- Multiple instances behind load balancer
- Stateless service, easy to scale
Job Submission Service:
- Stateless service
- Scale based on request rate
- Auto-scale: 10-100 instances
Scheduler Service:
- Multiple scheduler instances
- Use distributed locks to prevent duplicate scheduling
- Leader election for coordination
Executor Service:
- Multiple executor instances
- Each processes jobs from Kafka consumer group
- Scale based on queue depth
Worker Nodes:
- Add worker nodes as needed
- Auto-scale based on queue depth and resource utilization
- Support different node types (CPU-optimized, memory-optimized, GPU)
Database Scaling
Sharding Strategy:
- Shard jobs table by
user_id(hash-based) - Shard executions table by
job_id(hash-based) - Shard allocations table by
worker_node_id(hash-based)
Read Scaling:
- Multiple read replicas
- Route read queries to replicas
- Use read replicas for analytics queries
Caching Strategy
Multi-Level Caching:
- L1 Cache: In-memory cache in application (job status, worker metadata)
- L2 Cache: Redis (distributed cache)
- CDN: Cache static logs and outputs
Cache Invalidation:
- Event-driven invalidation on status updates
- TTL-based expiration
- Cache-aside pattern
Queue Scaling
Kafka Scaling:
- Multiple partitions per topic
- Multiple consumer instances per consumer group
- Scale consumers based on lag
Reliability and Fault Tolerance
Worker Node Failures
Detection:
- Heartbeat mechanism (every 30 seconds)
- Health check endpoints
- Automatic detection of unresponsive nodes
Recovery:
- Mark node as unhealthy
- Reschedule running jobs on failed node
- Release resources allocated to failed node
- Retry failed jobs
Implementation:
class WorkerNodeManager:
def check_worker_health(self):
workers = self.db.get_all_workers()
for worker in workers:
last_heartbeat = worker.last_heartbeat
time_since_heartbeat = datetime.now() - last_heartbeat
if time_since_heartbeat > timedelta(minutes=2):
# Worker is unhealthy
self.handle_worker_failure(worker)
def handle_worker_failure(self, worker):
# Mark worker as unhealthy
self.db.update_worker_node(
worker.node_id,
health_status='unhealthy',
status='inactive'
)
# Find running jobs on this worker
running_jobs = self.db.get_running_jobs_on_worker(worker.node_id)
# Reschedule jobs
for job in running_jobs:
# Mark execution as failed
self.db.update_execution(
job.execution_id,
status='failed',
error_message='Worker node failure'
)
# Release resources
self.resource_manager.release(job.allocation)
# Reschedule job
self.scheduler.reschedule_job(job)
Job Failure Handling
Retry Strategies:
- Exponential Backoff: Delay increases exponentially
- Fixed Delay: Constant delay between retries
- Immediate Retry: Retry immediately (for transient errors)
- Maximum Retries: Limit number of retries
Error Classification:
- Transient Errors: Network issues, temporary resource unavailability
- Permanent Errors: Invalid command, missing dependencies
- User Errors: Invalid input, permission denied
Implementation:
def should_retry(self, job, execution, error):
# Check max retries
if execution.retry_count >= job.max_retries:
return False
# Check error type
if self.is_permanent_error(error):
return False
# Check timeout
if execution.duration_ms > job.max_execution_time * 1000:
return False
return True
Database Failures
Failover:
- Automatic failover to replica
- Use connection pool with failover support
- Retry failed transactions
Data Consistency:
- Use transactions for critical operations
- Idempotent operations
- Eventual consistency for non-critical data
Network Partitions
Handling:
- Circuit breakers for external services
- Queue buffering during partitions
- Graceful degradation
- Health checks and automatic recovery
Fintech-Specific Considerations
Audit Trail
Requirements:
- Log all job submissions
- Log all status changes
- Log all resource allocations
- Retain logs per regulatory requirements (7 years)
Implementation:
- Immutable audit log table
- Archive old logs to S3
- Compliance reporting capabilities
Security
Authentication:
- API key authentication
- OAuth 2.0 for user-facing APIs
- Service-to-service authentication
Authorization:
- Role-based access control (RBAC)
- Job-level permissions
- Resource quota per user/team
Data Protection:
- Encrypt sensitive job data at rest
- Encrypt data in transit (TLS)
- Secure job execution environments
- Isolate job execution (sandboxing)
Compliance
Data Retention:
- Job metadata: 7 years
- Execution logs: 7 years
- Audit logs: 7 years
Reporting:
- Job execution reports
- Resource utilization reports
- Failure analysis reports
Monitoring and Observability
Key Metrics
Job Metrics:
- Jobs submitted per minute
- Jobs completed per minute
- Jobs failed per minute
- Average job execution time
- Job success rate
- Queue depth
Resource Metrics:
- CPU utilization per worker node
- Memory utilization per worker node
- Resource allocation rate
- Resource utilization efficiency
System Metrics:
- API latency (p50, p95, p99)
- Database query latency
- Queue processing latency
- Worker node availability
Alerting
Critical Alerts:
- Job failure rate > 5%
- Queue depth > 1M
- Worker node failure rate > 10%
- API error rate > 1%
Warning Alerts:
- Job execution latency > 1 hour (p95)
- Resource utilization > 80%
- Queue depth > 100K
- Worker node health degradation
Trade-offs and Design Decisions
Database vs. Message Queue
Decision: Use both
- Database: For job metadata, queries, consistency
- Message Queue: For async processing, scalability
Trade-off: Added complexity vs. better scalability
Synchronous vs. Asynchronous Scheduling
Decision: Asynchronous
- Why: Better scalability, decoupled components
- Trade-off: Slight delay vs. better throughput
Priority-Based vs. Fair Share Scheduling
Decision: Hybrid approach
- Why: Priority for important jobs, fair share to prevent starvation
- Trade-off: Complexity vs. fairness
Strong Consistency vs. Eventual Consistency
Decision: Strong consistency for critical data, eventual for status
- Why: Financial systems need consistency for job metadata
- Trade-off: Performance vs. consistency
Failure Scenarios
Worker Node Crash During Job Execution
Scenario: Worker node crashes while job is running
Handling:
- Detect node failure via heartbeat timeout
- Mark node as unhealthy
- Find running jobs on failed node
- Mark executions as failed
- Release resource allocations
- Reschedule jobs with retry
Scheduler Service Failure
Scenario: Scheduler service crashes
Handling:
- Multiple scheduler instances (redundancy)
- Leader election for coordination
- Jobs remain in queue
- Scheduler resumes from queue on restart
Database Failure
Scenario: Primary database fails
Handling:
- Automatic failover to replica
- Queue jobs for later processing
- Retry failed operations
- Maintain job state in cache temporarily
Queue Failure
Scenario: Kafka broker fails
Handling:
- Kafka replication (multiple brokers)
- Persist critical jobs to database as backup
- Resume from database when queue recovers
- Idempotent job processing
What Interviewers Look For
Distributed Systems Skills
- Job Scheduling Architecture
- Scheduler design
- Worker node management
- Resource allocation
- Red Flags: Single scheduler, no worker management, poor allocation
- Reliability & Guarantees
- At-least-once vs exactly-once
- Job persistence
- Failure handling
- Red Flags: No guarantees, job loss, no persistence
- Consistency Models
- Strong consistency for job state
- Eventual consistency for metrics
- Red Flags: Wrong consistency model, no understanding
Problem-Solving Approach
- SLA Handling
- SLA monitoring
- Violation detection
- Timeout mechanisms
- Red Flags: No SLA handling, no monitoring, no timeouts
- Edge Cases
- Long-running jobs
- Job dependencies
- Resource exhaustion
- Red Flags: Ignoring edge cases, no dependency handling
- Trade-off Analysis
- Consistency vs availability
- Performance vs reliability
- Red Flags: No trade-offs, dogmatic choices
System Design Skills
- Component Design
- Scheduler service
- Worker nodes
- Job store
- Red Flags: Monolithic, unclear boundaries
- Message Queue Usage
- Kafka/queue for job distribution
- Event-driven architecture
- Red Flags: No queue, synchronous processing
- Database Design
- Job persistence
- State management
- Proper indexing
- Red Flags: No persistence, poor state management
Communication Skills
- Architecture Explanation
- Clear scheduler design
- Job lifecycle understanding
- Red Flags: Unclear design, no lifecycle
- Guarantee Explanation
- Can explain at-least-once/exactly-once
- Understands trade-offs
- Red Flags: No understanding, vague explanations
Meta-Specific Focus
- Reliability Engineering
- Strong guarantees understanding
- Fault tolerance design
- Key: Show reliability expertise
- Distributed Systems Mastery
- Consistency models
- Failure handling
- Key: Demonstrate distributed systems knowledge
Conclusion
Designing a distributed job scheduler system that supports defining and running jobs on a schedule requires addressing all six core requirements:
1. Creating Jobs ✅
- REST API for job creation with comprehensive validation
- Support for different job types (one-time, recurring, scheduled, cron-based)
- Job dependencies and configuration management
- All job definitions persisted with ACID guarantees
2. Scheduling and Running Jobs ✅
- Efficient scheduling algorithms (priority-based, resource-aware, fair share)
- Resource allocation and worker node management
- Support for different execution environments (Docker, Kubernetes, VMs)
- Automatic job execution when resources are available
3. Reporting Failures and Successes ✅
- Comprehensive failure reporting with error classification
- Success metrics tracking (execution time, resource usage, output size)
- Failure/success rate aggregation per job, user, and team
- Detailed error messages, stack traces, and failure analysis
4. Reliability and Strong Guarantees ✅
- At-least-once execution: Jobs execute at least once (with retries)
- Exactly-once semantics: For idempotent jobs with idempotency keys
- No job loss guarantee: All jobs persisted to database, never lost
- Guaranteed execution: Scheduled jobs execute if resources available
- Atomic state transitions: Job status changes are atomic and consistent
- Data durability: All writes persisted with strong consistency
5. Viewing Logs and Status ✅
- Real-time job status tracking (queued, scheduled, running, completed, failed)
- Execution logs (stdout, stderr) with real-time streaming
- Historical job executions with full details
- Log search and filtering capabilities
- Comprehensive execution history and analytics
6. Handling SLA Violations (Long-Running Jobs) ✅
- SLA definition per job (expected time, max time)
- Real-time SLA monitoring during execution
- SLA violation detection and handling
- Configurable SLA policies (strict, flexible, warning-only)
- SLA compliance tracking and reporting
- Automatic timeout and kill for jobs exceeding max execution time
Key Design Decisions:
- PostgreSQL for strong consistency and ACID guarantees
- Kafka for async job processing and event streaming
- Redis for caching and real-time status updates
- Kubernetes for container orchestration and resource management
- S3 for durable log storage and archival
- Elasticsearch for log search and analytics
Key Takeaways:
- Strong guarantees are critical: Use transactions, idempotency keys, and durable storage
- Comprehensive monitoring: Track everything - status, logs, SLA, failures, successes
- SLA handling is essential: Monitor execution time, handle violations appropriately
- Design for horizontal scaling: All components must scale independently
- Plan for failures: Worker failures, network partitions, database failures
- Fintech-specific requirements: Compliance, audit trails, security, data retention
This system design demonstrates understanding of:
- Distributed systems: Scalability, consistency, fault tolerance
- Resource management: Allocation, scheduling, optimization
- Reliability engineering: Strong guarantees, at-least-once/exactly-once semantics
- Observability: Logging, monitoring, SLA tracking, failure reporting
- Fintech requirements: Compliance, security, audit trails
All critical for building production-grade job scheduler systems at fintech companies.